|
6 | 6 | "metadata": {}, |
7 | 7 | "outputs": [], |
8 | 8 | "source": [ |
9 | | - "import sys\n", |
10 | | - "if 'google.colab' in sys.modules:\n", |
11 | | - " !wget https://raw.githubusercontent.com/yandexdataschool/Practical_RL/0ccb0673965dd650d9b284e1ec90c2bfd82c8a94/week08_pomdp/atari_util.py\n", |
12 | | - " !wget https://raw.githubusercontent.com/yandexdataschool/Practical_RL/0ccb0673965dd650d9b284e1ec90c2bfd82c8a94/week08_pomdp/env_pool.py\n", |
13 | | - "\n", |
14 | | - " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/setup_colab.sh -O- | bash\n", |
15 | | - " !touch .setup_complete\n", |
16 | | - "# If you are running on a server, launch xvfb to record game videos\n", |
17 | | - "# Please make sure you have xvfb installed\n", |
18 | | - "import os\n", |
19 | | - "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n", |
20 | | - " !bash ../xvfb start\n", |
21 | | - " os.environ['DISPLAY'] = ':1'" |
| 9 | + "import sys, os\n", |
| 10 | + "if 'google.colab' in sys.modules and not os.path.exists('.setup_complete'):\n", |
| 11 | + " # Install xvfb and our launcher script for it\n", |
| 12 | + " !apt-get install -y xvfb\n", |
| 13 | + " !wget -q https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/xvfb -O ../xvfb\n", |
| 14 | + "\n", |
| 15 | + " !pip install gym[atari,accept-rom-license]\n", |
| 16 | + "\n", |
| 17 | + " !wget https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/week08_pomdp/atari_util.py\n", |
| 18 | + " !wget https://raw.githubusercontent.com/yandexdataschool/Practical_RL/master/week08_pomdp/env_pool.py\n", |
| 19 | + "\n", |
| 20 | + " !touch .setup_complete\n", |
| 21 | + "\n", |
| 22 | + "# This code creates a virtual display to draw game images on.\n", |
| 23 | + "# It will have no effect if your machine has a monitor.\n", |
| 24 | + "import os\n", |
| 25 | + "if type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\")) == 0:\n", |
| 26 | + " !bash ../xvfb start\n", |
| 27 | + " os.environ['DISPLAY'] = ':1'" |
22 | 28 | ] |
23 | 29 | }, |
24 | 30 | { |
|
53 | 59 | "name": "stdout", |
54 | 60 | "output_type": "stream", |
55 | 61 | "text": [ |
56 | | - "\u001b[33mWARN: gym.spaces.Box autodetected dtype as <class 'numpy.float32'>. Please provide explicit dtype.\u001b[0m\n", |
57 | 62 | "Observation shape: (1, 42, 42)\n", |
58 | 63 | "Num actions: 14\n", |
59 | 64 | "Action names: ['NOOP', 'UP', 'RIGHT', 'LEFT', 'DOWN', 'DOWNRIGHT', 'DOWNLEFT', 'RIGHTFIRE', 'LEFTFIRE', 'DOWNFIRE', 'UPRIGHTFIRE', 'UPLEFTFIRE', 'DOWNRIGHTFIRE', 'DOWNLEFTFIRE']\n" |
|
70 | 75 | " env = PreprocessAtari(env, height=42, width=42,\n", |
71 | 76 | " crop=lambda img: img[60:-30, 15:],\n", |
72 | 77 | " color=False, n_frames=1)\n", |
| 78 | + " env.metadata['render_fps'] = 30\n", |
73 | 79 | " return env\n", |
74 | 80 | "\n", |
75 | 81 | "\n", |
|
143 | 149 | "\n", |
144 | 150 | "Let's design another agent that has a recurrent neural net memory to solve this. Here's a sketch.\n", |
145 | 151 | "\n", |
146 | | - "\n" |
| 152 | + "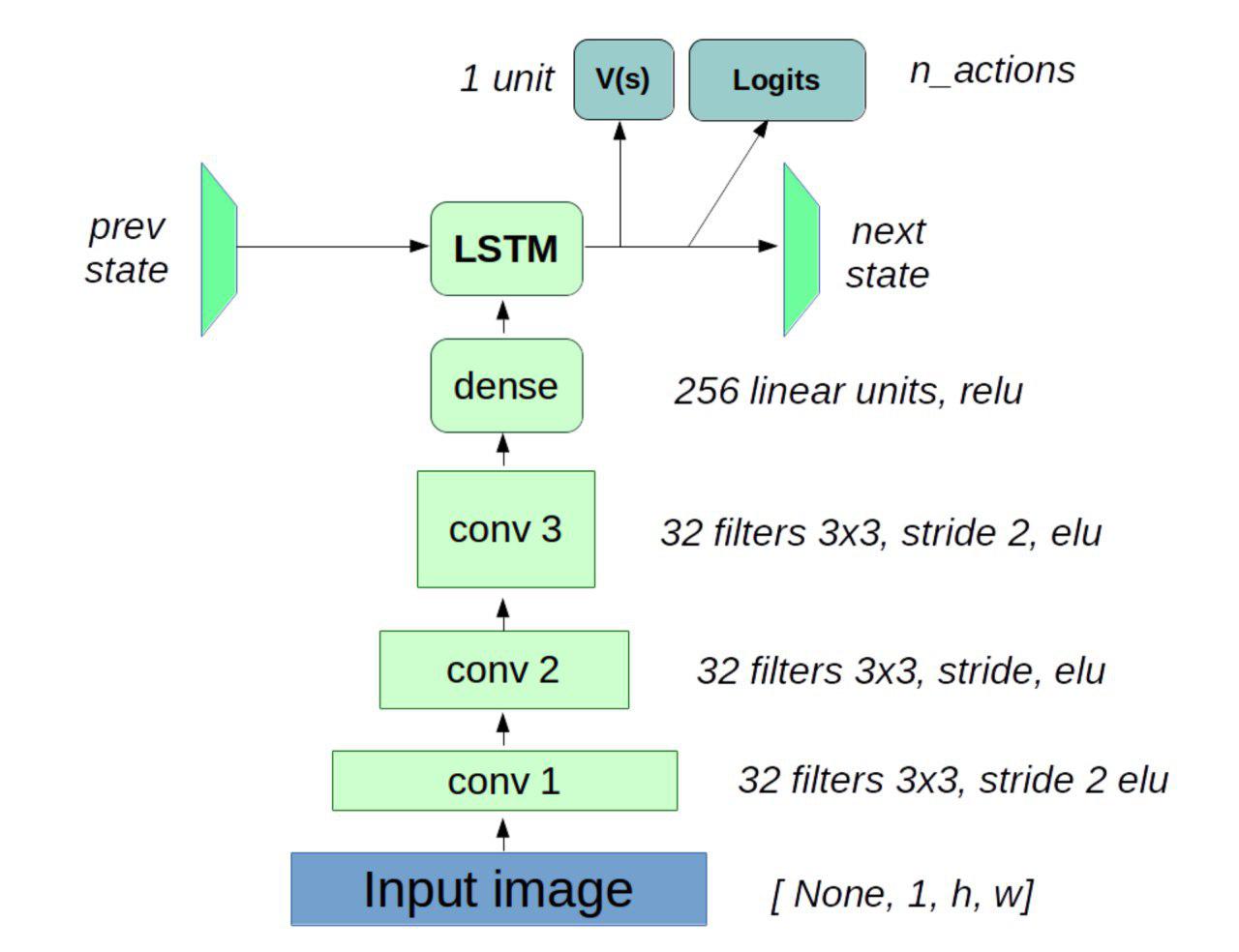\n" |
147 | 153 | ] |
148 | 154 | }, |
149 | 155 | { |
|
204 | 210 | " return new_state, (logits, state_value)\n", |
205 | 211 | "\n", |
206 | 212 | " def get_initial_state(self, batch_size):\n", |
207 | | - " \"\"\"Return a list of agent memory states at game start. Each state is a np array of shape [batch_size, ...]\"\"\"\n", |
208 | | - " return torch.zeros((batch_size, 128)), torch.zeros((batch_size, 128))\n", |
| 213 | + " \"\"\"Return the agent memory state at the beginning of the game. Each state is a np array of shape [batch_size, ...]\"\"\"\n", |
| 214 | + " h0 = torch.zeros((batch_size, 128))\n", |
| 215 | + " c0 = torch.zeros((batch_size, 128))\n", |
| 216 | + " return h0, c0\n", |
209 | 217 | "\n", |
210 | 218 | " def sample_actions(self, agent_outputs):\n", |
211 | 219 | " \"\"\"pick actions given numeric agent outputs (np arrays)\"\"\"\n", |
212 | 220 | " logits, state_values = agent_outputs\n", |
213 | | - " probs = F.softmax(logits)\n", |
| 221 | + " probs = F.softmax(logits, dim=-1)\n", |
214 | 222 | " return torch.multinomial(probs, 1)[:, 0].data.numpy()\n", |
215 | 223 | "\n", |
216 | 224 | " def step(self, prev_state, obs_t):\n", |
|
258 | 266 | "metadata": {}, |
259 | 267 | "outputs": [], |
260 | 268 | "source": [ |
| 269 | + "import tqdm\n", |
| 270 | + "\n", |
261 | 271 | "def evaluate(agent, env, n_games=1):\n", |
262 | 272 | " \"\"\"Plays an entire game start to end, returns session rewards.\"\"\"\n", |
263 | 273 | "\n", |
264 | 274 | " game_rewards = []\n", |
265 | | - " for _ in range(n_games):\n", |
| 275 | + " for _ in tqdm.notebook.trange(n_games):\n", |
266 | 276 | " # initial observation and memory\n", |
267 | 277 | " observation = env.reset()\n", |
268 | 278 | " prev_memories = agent.get_initial_state(1)\n", |
|
292 | 302 | "source": [ |
293 | 303 | "import gym.wrappers\n", |
294 | 304 | "\n", |
295 | | - "with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n", |
| 305 | + "with gym.wrappers.RecordVideo(make_env(), video_folder=\"videos\") as env_monitor:\n", |
296 | 306 | " rewards = evaluate(agent, env_monitor, n_games=3)\n", |
297 | 307 | "\n", |
298 | 308 | "print(rewards)" |
|
336 | 346 | "### Training on parallel games\n", |
337 | 347 | "\n", |
338 | 348 | "We introduce a class called EnvPool - it's a tool that handles multiple environments for you. Here's how it works:\n", |
339 | | - "" |
| 349 | + "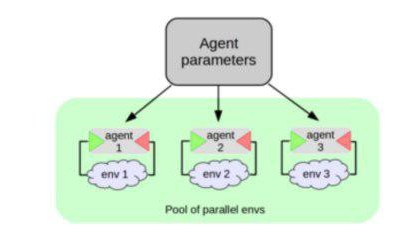" |
340 | 350 | ] |
341 | 351 | }, |
342 | 352 | { |
|
354 | 364 | "metadata": {}, |
355 | 365 | "source": [ |
356 | 366 | "We gonna train our agent on a thing called __rollouts:__\n", |
357 | | - "\n", |
| 367 | + "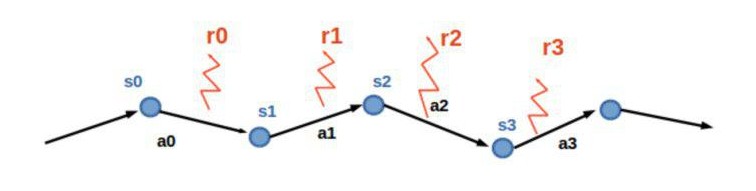\n", |
358 | 368 | "\n", |
359 | 369 | "A rollout is just a sequence of T observations, actions and rewards that agent took consequently.\n", |
360 | 370 | "* First __s0__ is not necessarily initial state for the environment\n", |
|
446 | 456 | "source": [ |
447 | 457 | "def to_one_hot(y, n_dims=None):\n", |
448 | 458 | " \"\"\" Take an integer tensor and convert it to 1-hot matrix. \"\"\"\n", |
449 | | - " y_tensor = y.to(dtype=torch.int64).view(-1, 1)\n", |
| 459 | + " y_tensor = y.to(dtype=torch.int64).reshape(-1, 1)\n", |
450 | 460 | " n_dims = n_dims if n_dims is not None else int(torch.max(y_tensor)) + 1\n", |
451 | 461 | " y_one_hot = torch.zeros(y_tensor.size()[0], n_dims).scatter_(1, y_tensor, 1)\n", |
452 | 462 | " return y_one_hot" |
|
472 | 482 | " states = torch.tensor(np.asarray(states), dtype=torch.float32)\n", |
473 | 483 | " actions = torch.tensor(np.array(actions), dtype=torch.int64) # shape: [batch_size, time]\n", |
474 | 484 | " rewards = torch.tensor(np.array(rewards), dtype=torch.float32) # shape: [batch_size, time]\n", |
475 | | - " is_not_done = torch.tensor(np.array(is_not_done), dtype=torch.float32) # shape: [batch_size, time]\n", |
| 485 | + " is_not_done = torch.tensor(np.array(is_not_done), dtype=torch.bool) # shape: [batch_size, time]\n", |
476 | 486 | " rollout_length = rewards.shape[1] - 1\n", |
477 | 487 | "\n", |
478 | 488 | " # predict logits, probas and log-probas using an agent.\n", |
|
483 | 493 | " for t in range(rewards.shape[1]):\n", |
484 | 494 | " obs_t = states[:, t]\n", |
485 | 495 | "\n", |
486 | | - " # use agent to comute logits_t and state values_t.\n", |
| 496 | + " # use agent to compute logits_t and state values_t.\n", |
487 | 497 | " # append them to logits and state_values array\n", |
488 | 498 | "\n", |
489 | 499 | " memory, (logits_t, values_t) = <YOUR CODE>\n", |
|
521 | 531 | " V_next = state_values[:, t + 1].detach() # next state values\n", |
522 | 532 | " # log-probability of a_t in s_t\n", |
523 | 533 | " logpi_a_s_t = logprobas_for_actions[:, t]\n", |
| 534 | + " is_not_done_t = is_not_done[:, t]\n", |
524 | 535 | "\n", |
525 | 536 | " # update G_t = r_t + gamma * G_{t+1} as we did in week6 reinforce\n", |
526 | | - " cumulative_returns = G_t = r_t + gamma * cumulative_returns\n", |
| 537 | + " cumulative_returns = G_t = r_t + torch.where(is_not_done_t, gamma * cumulative_returns, 0)\n", |
527 | 538 | "\n", |
528 | 539 | " # Compute temporal difference error (MSE for V(s))\n", |
529 | 540 | " value_loss += <YOUR CODE>\n", |
|
579 | 590 | "outputs": [], |
580 | 591 | "source": [ |
581 | 592 | "from IPython.display import clear_output\n", |
582 | | - "from tqdm import trange\n", |
583 | 593 | "from pandas import DataFrame\n", |
584 | 594 | "moving_average = lambda x, **kw: DataFrame(\n", |
585 | 595 | " {'x': np.asarray(x)}).x.ewm(**kw).mean().values\n", |
|
593 | 603 | "metadata": {}, |
594 | 604 | "outputs": [], |
595 | 605 | "source": [ |
596 | | - "for i in trange(15000):\n", |
| 606 | + "log_every = 100\n", |
| 607 | + "\n", |
| 608 | + "for i in tqdm.trange(15000):\n", |
| 609 | + " # tqdm.notebook.tqdm is not trivial to use here because clear_output(True)\n", |
| 610 | + " # also removes the tqdm widget\n", |
597 | 611 | "\n", |
598 | 612 | " memory = list(pool.prev_memory_states)\n", |
599 | | - " rollout_obs, rollout_actions, rollout_rewards, rollout_mask = pool.interact(\n", |
600 | | - " 10)\n", |
601 | | - " train_on_rollout(rollout_obs, rollout_actions,\n", |
602 | | - " rollout_rewards, rollout_mask, memory)\n", |
| 613 | + " rollout_obs, rollout_actions, rollout_rewards, rollout_mask = pool.interact(10)\n", |
| 614 | + " train_on_rollout(rollout_obs, rollout_actions, rollout_rewards, rollout_mask, memory)\n", |
603 | 615 | "\n", |
604 | | - " if i % 100 == 0:\n", |
| 616 | + " if i % log_every == 0:\n", |
605 | 617 | " rewards_history.append(np.mean(evaluate(agent, env, n_games=1)))\n", |
606 | 618 | " clear_output(True)\n", |
607 | | - " plt.plot(rewards_history, label='rewards')\n", |
608 | | - " plt.plot(moving_average(np.array(rewards_history),\n", |
609 | | - " span=10), label='rewards ewma@10')\n", |
| 619 | + " plt.plot(\n", |
| 620 | + " np.arange(len(rewards_history)) * log_every,\n", |
| 621 | + " rewards_history, label='rewards')\n", |
| 622 | + " plt.plot(\n", |
| 623 | + " np.arange(len(rewards_history)) * log_every,\n", |
| 624 | + " moving_average(np.array(rewards_history), span=10), label='rewards ewma@10')\n", |
610 | 625 | " plt.legend()\n", |
| 626 | + " plt.grid()\n", |
611 | 627 | " plt.show()\n", |
612 | 628 | " if rewards_history[-1] >= 10000:\n", |
613 | 629 | " print(\"Your agent has just passed the minimum homework threshold\")\n", |
|
628 | 644 | "Since we use a policy-based method, we also keep track of __policy entropy__ - the same one you used as a regularizer. The only important thing about it is that your entropy shouldn't drop too low (`< 0.1`) before your agent gets the yellow belt. Or at least it can drop there, but _it shouldn't stay there for long_.\n", |
629 | 645 | "\n", |
630 | 646 | "If it does, the culprit is likely:\n", |
631 | | - "* Some bug in entropy computation. Remember that it is $ - \\sum p(a_i) \\cdot log p(a_i) $\n", |
| 647 | + "* Some bug in entropy computation. Remember that it is $ - \\sum p(a_i) \\cdot \\log p(a_i) $\n", |
632 | 648 | "* Your agent architecture converges too fast. Increase entropy coefficient in actor loss. \n", |
633 | 649 | "* Gradient explosion - just [clip gradients](https://stackoverflow.com/a/56069467) and maybe use a smaller network\n", |
634 | 650 | "* Us. Or PyTorch developers. Or aliens. Or lizardfolk. Contact us on forums before it's too late!\n", |
|
651 | 667 | "source": [ |
652 | 668 | "import gym.wrappers\n", |
653 | 669 | "\n", |
654 | | - "with gym.wrappers.Monitor(make_env(), directory=\"videos\", force=True) as env_monitor:\n", |
| 670 | + "with gym.wrappers.RecordVideo(make_env(), video_folder=\"videos\") as env_monitor:\n", |
655 | 671 | " final_rewards = evaluate(agent, env_monitor, n_games=20)\n", |
656 | 672 | "\n", |
657 | 673 | "print(\"Final mean reward\", np.mean(final_rewards))" |
|
0 commit comments