Deploy Fuseki and Rhizomer
Rhizomer can explore the data available from RDF graph stores through SPARQL. The Rhizomer's frontend and backend can be deployed together using Docker to explore existing SPARQL endpoints as detailed in Deploy using Docker
To experiment with Rhizomer from scratch, if you don't have already an RDF store available, the following docker-compose deploys both the Rhizomer's frontend and backend together with Fuseki, and RDF store including a SPARQL endpoint.
To deploy using Docker, install it for Mac, Windows or Linux from: https://docs.docker.com/get-docker
Then, also instal docker-compose to be able to configure the deployment using a docker-compose YAML file.
The docker-compose YAML file, presented next, provides a simple deployment including the frontend available from http://localhost and connecting to a backend deployed at http://localhost:8080. The default user is admin with the default password password. The default values for the password or the deployment locations can be edited or configured by setting the corresponding environment variables. Finally, a Fuseki RDF store is deployed at http://localhost:3030.
version: '3'
services:
rhizomer:
image: rhizomik/rhizomer-eye
container_name: rhizomer
ports:
- "80:80"
environment:
- API_URL=${API_URL:-http://localhost:8080}
rhizomer-api:
image: rhizomik/rhizomer-api
container_name: rhizomer-api
ports:
- "8080:8080"
environment:
- ALLOWED_ORIGINS=${CLIENT_URL:-http://localhost}
- RHIZOMER_DEFAULT_PASSWORD=password
fuseki:
image: secoresearch/fuseki
container_name: fuseki
ports:
- "3030:3030"
environment:
- ENABLE_UPLOAD=true
- ENABLE_UPDATE=true
- ENABLE_DATA_WRITE=true
- ADMIN_PASSWORD=passwordTo use the docker-compose file, copy the previous content to a local file named docker-compose.yml and from the folder where the file is saved typed the following command:
docker-compose up -dFor production ready deployments, including persistence of Rhizomer API using a database, there is a sample docker-compose.yml at Deploy using Docker.
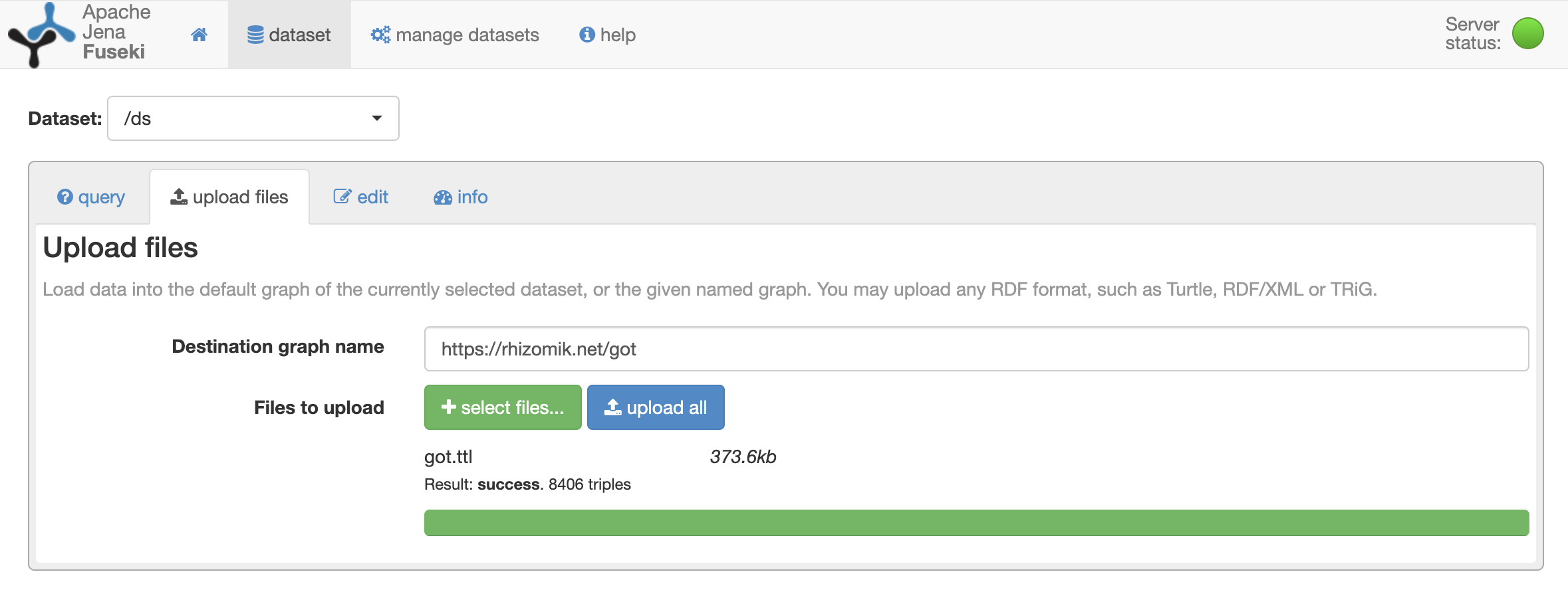
To have access to some sample RDF data to be explored from Rhizomer through a SPARQL endpoint, we first load it into Fuseki. Fuseki's is available from http://localhost:3030. Log in using user admin and the password configured in the docker-compose.yml, for instance password.

Then, using Fuseki web user interface, click the add data button for the dataset named /ds, which is created by default. First, configure the destination graph name, for instance type https://rhizomik.net/got. The sample data we are going to use is available online as got.ttl. Download it as file got.ttl and then select this file to be uploaded to Fuseki. To finally trigger the upload, click upload now. The 8406 RDF triples contained in the file are now stored in Fuseki.
Now we will interact with Rhizomer using its frontend. Following the previous docker-compose.yml, it should be available from http://localhost.

To manage users and registered datasets, sign in with the username admin and the default password provided in the docker-compose.yml during deployment, for instance password.
We can now define a new dataset to explore.
- On the Rhizomer website, choose
Datasetsfrom the top navigation bar. - Choose
Newfrom the dropdown. - Name your Rhizomer dataset, for instance
got. - To make the dataset viewable by other users, make it
Public. - For
Query Type, choose the type of exploration, in this caseDetailed.

- After clicking
Submit, provide theSPARQL Server type¸ chooseGeneric. - Configure the SPARQL endpoint for querying:
http://fuseki:3030/ds/sparql. Fuseki is configured readable for anyone, so no need to make the endpoint password protected. - We will configure the endpoint as
writable, so it is also possible to upload data directly from Rhizomer. - The SPARQL Update endpoint is:
http://fuseki:3030/ds/update, with usernameadminand passwordpassword.

- Then, after clicking
Submit, the endpoint is inspected and the available graphs are presented. Select the only available graph, the one we use when uploading the sample data to Fuseki:https://rhizomik.net/got.- Note that, if the endpoint is
writable, it is possible to create new graphs and load data into them through Rhizomer. - Graphs can be loaded as
dataorontology. Those loaded asdatawill be combined and explored.Ontologiesare used, for the moment, to retrieve classes and properties labels.
- Note that, if the endpoint is

- Finally, click Submit to complete the Rhizomer dataset creation.

When we choose Explore on the dataset detail page, we can start inspecting the data we loaded into Fuseki. The first thing Rhizomer does when interacting with a dataset is present an overview of the data:
- A word cloud generated from the classes in the dataset, if the dataset
Query Typewas set toOptimized. Each word in the cloud corresponds to a class, and its size is relative to the number of instances of the class in the dataset. - A network overview of the main classes and relationships among them, if the dataset
Query Typewas set toDetailed.
In this case, as we set it to Detailed, a network overview is presented. There are four classes: FictionalCharacter, Noble, Book, and Organisation. All the characters in the dataset are instances of FictionalCharacter, but some of them are also Noble. They appear in Books and have allegiance with houses, which are Organisations.

We can choose a class to explore it further. For example, if we choose Noble, we see the following faceted view of all Game of Thrones characters classified as nobles.

This view shows the number of instances for the selected class, initially unconstrained so all 430 of 430 nobles are listed. The view also lists the facets for the class. Each facet corresponds to a property used to describe instances, and you can see how many times the corresponding property is used. You can also see how many different values are used and whether all are literals or not. You can expand each facet to show the 10 most common values for the selected instances.
From this visualization, you can further filter the available instance by one or more specific facet values. There is also an input form for each facet that allows filtering by any of the values.
As we mentioned earlier, Rhizomer also works as a linked data browser, so if you choose any resource in the instance descriptions, its description is retrieved and presented if available locally or remotely, from the resource URL. For instance, if you click on the book "A Game of Thrones", which is the value of the property "appearsIn" for some characters, the local data is complemented with all that is available remotely from the book URI, in this case from DBpedia:

You don't need any prior knowledge about the dataset to explore it, because the overview and faceted views inform you of what classes are present in the dataset and how they're described using properties and values. Rhizomer does all the hard work through SPARQL queries, so you don't need to worry about it.
You can also try Rhizomer to explore the Game of Thrones dataset at: https://rhizomer.rhizomik.net/datasets/got